
Локальные AI-агенты уже не выглядят как игрушка для энтузиастов. Если задача не требует свежего веб-поиска, доступа к закрытым API или мощности frontier-моделей, связка Ollama + LangGraph позволяет собрать приватную агентную систему, которая работает на вашем ПК, рабочей станции или локальном сервере.
Смысл не в том, чтобы заменить облачные модели во всех сценариях. Смысл в другом: вынести повторяемую интеллектуальную работу ближе к данным, не отправлять документы наружу, не платить за каждый эксперимент и получить контроль над тем, как агенты планируют, спорят, сохраняют состояние и восстанавливаются после ошибок.
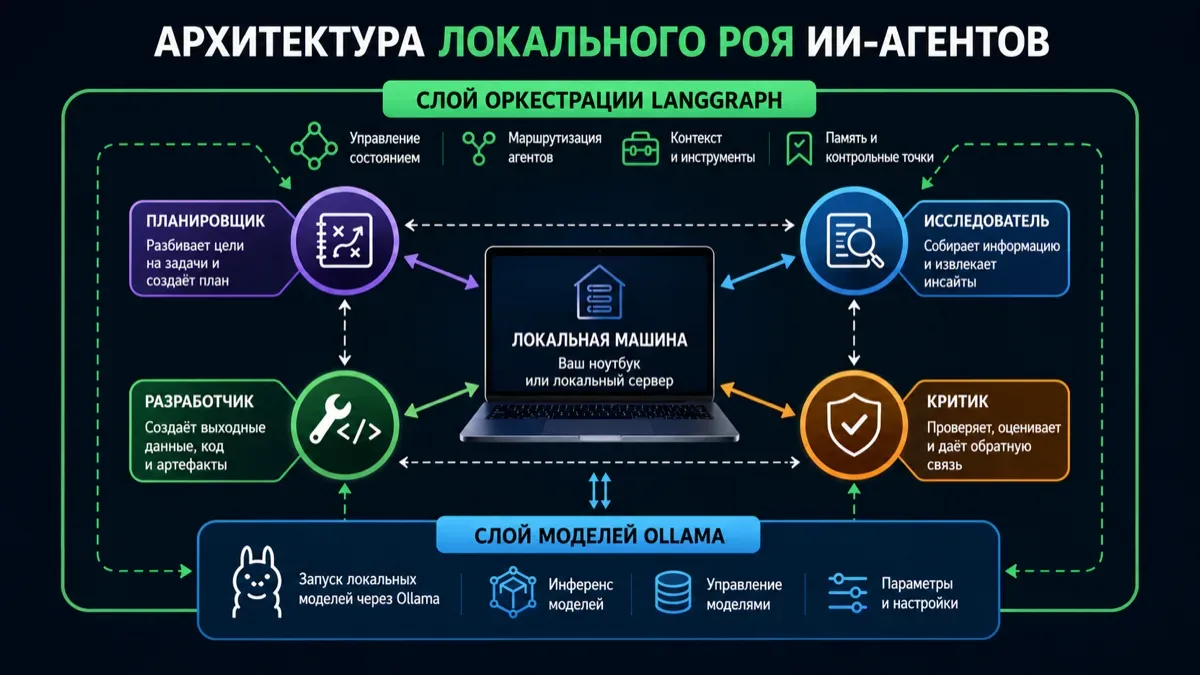
Ниже — практический скелет локального роя: планировщик, исследователь, строитель и критик. Его можно использовать как основу для анализа документов, подготовки отчетов, ревью кода, внутренних ассистентов и приватных RAG-процессов.
Что мы собираем
В этой архитектуре Ollama отвечает за локальный запуск модели, а LangGraph — за управление состоянием и переходами между агентами. Это важное разделение: модель генерирует ответы, но граф решает, кто ходит следующим, где хранится прогресс и когда задача считается завершенной.
Итоговая схема:
- supervisor/planner принимает цель и выбирает следующего агента;
- researcher читает локальные файлы и собирает факты;
- builder превращает факты в черновик решения;
- critic ищет ошибки, пробелы и рискованные допущения;
- finalizer собирает финальный ответ;
- SQLite-checkpointer сохраняет состояние между шагами.
Такой рой не обязан быть большим. На практике четыре роли часто полезнее, чем десять: меньше хаоса в маршрутизации, проще отлаживать промпты, легче понять, почему система зациклилась или приняла плохое решение.
Что нужно перед стартом
Ориентиры по железу зависят от модели, квантования и размера контекста. Для 7B-8B моделей обычно достаточно современного ноутбука или мини-ПК с 16 ГБ RAM, но комфортнее работать с 32 ГБ. Для 14B и 30B стоит закладывать больше памяти и, если есть возможность, GPU. Если локальное железо не тянет нужный размер модели, можно временно вынести тяжелые запуски на GPU-провайдера вроде RunPod, но тогда приватность уже зависит от вашей облачной конфигурации.
Для руководства используем Python 3.10+, Ollama и LangGraph v1.x. Модель можно выбрать любую совместимую с Ollama. Хороший старт — qwen3:8b: в библиотеке Ollama семейство Qwen3 помечено как поддерживающее agent/tool-oriented сценарии, а размер 8B остается реалистичным для локального запуска. Для англоязычных задач и длинного контекста также часто берут llama3.1:8b.
Установка:
# macOS / Linux: установка Ollama описана на сайте проекта
ollama pull qwen3:8b
python -m venv .venv
source .venv/bin/activate
pip install -U langgraph langchain-ollama langchain-core langgraph-checkpoint-sqliteПроверьте, что локальный сервер Ollama доступен:
ollama run qwen3:8bПо умолчанию Ollama поднимает локальный API на localhost:11434. У него есть OpenAI-compatible endpoints, включая chat completions, JSON mode, streaming и tools, но в этом примере мы пойдем через официальный пакет langchain-ollama, чтобы проще подключить модель к LangGraph.
Минимальный рой на LangGraph
Создайте файл local_swarm.py. Код ниже намеренно оставлен компактным: это не production-фреймворк, а понятная база, которую можно расширять инструментами, RAG, проверками прав и UI.
from __future__ import annotations
import json
import operator
import os
from pathlib import Path
from typing import Annotated, Literal, TypedDict
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_ollama import ChatOllama
from langgraph.checkpoint.sqlite import SqliteSaver
from langgraph.graph import END, START, StateGraph
MODEL = os.environ.get('LOCAL_MODEL', 'qwen3:8b')
WORKSPACE = Path(os.environ.get('SWARM_WORKSPACE', '.')).resolve()
MAX_ITERATIONS = int(os.environ.get('MAX_ITERATIONS', '6'))
llm = ChatOllama(
model=MODEL,
base_url=os.environ.get('OLLAMA_BASE_URL', 'http://localhost:11434'),
temperature=0.2,
num_ctx=8192,
)
json_llm = ChatOllama(
model=MODEL,
base_url=os.environ.get('OLLAMA_BASE_URL', 'http://localhost:11434'),
temperature=0,
format='json',
num_ctx=8192,
)
class SwarmState(TypedDict):
goal: str
task: str
draft: str
findings: Annotated[list[str], operator.add]
decisions: Annotated[list[str], operator.add]
errors: Annotated[list[str], operator.add]
iterations: int
next: str
def call_model(system: str, prompt: str, *, json_mode: bool = False) -> str:
model = json_llm if json_mode else llm
message = model.invoke([
SystemMessage(content=system),
HumanMessage(content=prompt),
])
return str(message.content).strip()
def parse_json_object(text: str) -> dict:
start = text.find('{')
end = text.rfind('}')
if start == -1 or end == -1 or end <= start:
return {}
try:
return json.loads(text[start:end + 1])
except json.JSONDecodeError:
return {}
def safe_path(relative_path: str) -> Path:
candidate = (WORKSPACE / relative_path).resolve()
if candidate != WORKSPACE and WORKSPACE not in candidate.parents:
raise ValueError('Path escapes workspace')
return candidate
def local_search(query: str, limit: int = 8) -> list[str]:
allowed_suffixes = {'.md', '.txt', '.py', '.json', '.yaml', '.yml'}
terms = [term.lower() for term in query.split() if len(term) > 2]
results: list[str] = []
for item in WORKSPACE.rglob('*'):
if len(results) >= limit:
break
if item.is_dir() or item.name.startswith('.'):
continue
if item.suffix.lower() not in allowed_suffixes:
continue
try:
text = item.read_text(errors='ignore')[:12000]
except OSError:
continue
lower = text.lower()
if not terms or any(term in lower for term in terms):
rel = item.relative_to(WORKSPACE)
snippet = text.replace('\n', ' ')[:700]
results.append(f'{rel}: {snippet}')
return results
def planner(state: SwarmState) -> dict:
if state.get('iterations', 0) >= MAX_ITERATIONS:
return {'next': 'final', 'task': 'Finish because iteration limit was reached'}
prompt = f'''
Goal: {state['goal']}
Current task: {state.get('task', '')}
Findings count: {len(state.get('findings', []))}
Draft exists: {bool(state.get('draft'))}
Recent errors: {state.get('errors', [])[-3:]}
Choose exactly one next step: researcher, builder, critic, final.
Return only JSON with keys next and task.
'''
raw = call_model('You are a strict workflow planner for a local multi-agent system.', prompt, json_mode=True)
data = parse_json_object(raw)
next_step = data.get('next', 'researcher')
if next_step not in {'researcher', 'builder', 'critic', 'final'}:
next_step = 'researcher'
return {'next': next_step, 'task': str(data.get('task', 'Continue the task'))}
def researcher(state: SwarmState) -> dict:
query = state.get('task') or state['goal']
hits = local_search(query)
if not hits:
return {
'findings': ['No matching local files found. Continue using only the user goal and existing state.'],
'iterations': state.get('iterations', 0) + 1,
}
prompt = 'Summarize the relevant facts from these local snippets. Do not invent facts.\n\n' + '\n\n'.join(hits)
summary = call_model('You are a local research agent. Use only provided snippets.', prompt)
return {
'findings': [summary],
'decisions': [f'Researcher searched local workspace for: {query}'],
'iterations': state.get('iterations', 0) + 1,
}
def builder(state: SwarmState) -> dict:
prompt = f'''
Goal: {state['goal']}
Task: {state.get('task', '')}
Findings:
{chr(10).join(state.get('findings', [])[-5:])}
Create a concrete answer or implementation plan. Mark assumptions explicitly.
'''
draft = call_model('You are a builder agent. Produce useful, testable output.', prompt)
return {
'draft': draft,
'decisions': ['Builder produced or updated the draft'],
'iterations': state.get('iterations', 0) + 1,
}
def critic(state: SwarmState) -> dict:
prompt = f'''
Goal: {state['goal']}
Draft:
{state.get('draft', '')}
Find factual risks, missing checks, security issues and unclear assumptions.
If the draft is good enough, say PASS and list only the remaining caveats.
'''
critique = call_model('You are a skeptical reviewer. Be concise and specific.', prompt)
return {
'errors': [critique],
'decisions': ['Critic reviewed the draft'],
'iterations': state.get('iterations', 0) + 1,
}
def finalizer(state: SwarmState) -> dict:
prompt = f'''
Goal: {state['goal']}
Draft:
{state.get('draft', '')}
Critique:
{chr(10).join(state.get('errors', [])[-3:])}
Produce the final answer. Keep caveats that matter. Do not mention internal agent names.
'''
final = call_model('You are the final editor of a local autonomous agent run.', prompt)
return {'draft': final, 'next': 'done'}
def route(state: SwarmState) -> Literal['researcher', 'builder', 'critic', 'final']:
value = state.get('next', 'researcher')
if value in {'researcher', 'builder', 'critic', 'final'}:
return value
return 'final'
def build_graph(checkpointer):
graph = StateGraph(SwarmState)
graph.add_node('planner', planner)
graph.add_node('researcher', researcher)
graph.add_node('builder', builder)
graph.add_node('critic', critic)
graph.add_node('final', finalizer)
graph.add_edge(START, 'planner')
graph.add_conditional_edges('planner', route)
graph.add_edge('researcher', 'planner')
graph.add_edge('builder', 'planner')
graph.add_edge('critic', 'planner')
graph.add_edge('final', END)
return graph.compile(checkpointer=checkpointer)
if __name__ == '__main__':
goal = os.environ.get('SWARM_GOAL') or 'Analyze the local project and suggest three high-impact improvements.'
initial_state: SwarmState = {
'goal': goal,
'task': '',
'draft': '',
'findings': [],
'decisions': [],
'errors': [],
'iterations': 0,
'next': 'researcher',
}
config = {'configurable': {'thread_id': 'local-swarm-demo'}}
with SqliteSaver.from_conn_string('swarm-checkpoints.sqlite') as checkpointer:
app = build_graph(checkpointer)
result = app.invoke(initial_state, config=config)
print('=== FINAL RESULT ===')
print(result['draft'])Запуск:
SWARM_WORKSPACE=./docs \
SWARM_GOAL='Найди пробелы в документации и предложи план улучшений' \
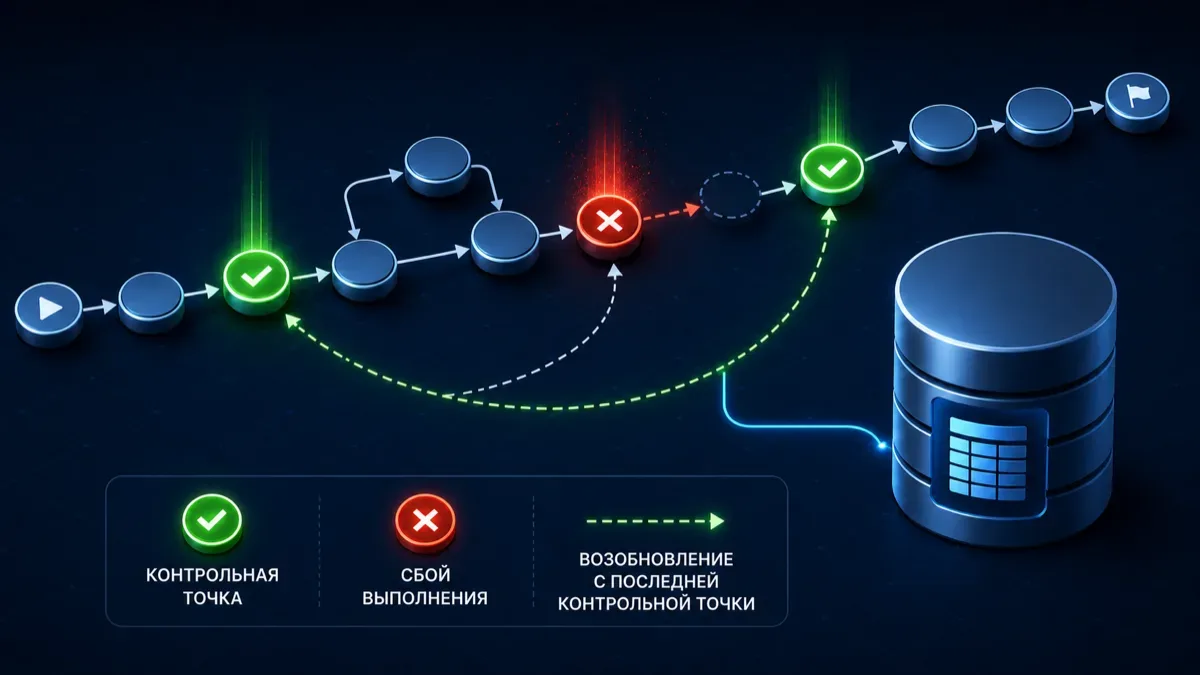
python local_swarm.pyПосле первого запуска рядом появится swarm-checkpoints.sqlite. Это не память модели, а история состояния графа: какие узлы уже прошли, какие поля состояния обновились, где можно продолжить выполнение.
Почему LangGraph здесь полезнее простого цикла
Самый простой агент — это while-цикл вокруг LLM: спросили модель, распарсили ответ, вызвали инструмент, снова спросили. Для демо этого достаточно. Для живой работы быстро появляются проблемы: модель забывает, что уже проверила; шаги трудно восстановить после падения; маршрутизация размазана по промптам; один неудачный ответ ломает весь процесс.
LangGraph решает это инженерно. Узлы графа — обычные Python-функции. Состояние типизировано. Переходы видны в коде. Чекпоинтер сохраняет прогресс. Если нужен human-in-the-loop, можно добавить остановку перед опасным действием: отправкой письма, записью файла, запуском команды, изменением тикета.
Важно: чекпоинт сохраняется на границах узлов. Если модель зависла внутри одного долгого вызова, граф не восстановит половину уже сгенерированного ответа. Поэтому тяжелые операции лучше дробить: отдельный узел для поиска, отдельный для чтения, отдельный для генерации, отдельный для проверки.
Как сделать рой менее хрупким
Локальные модели слабее лучших облачных систем в сложном рассуждении, длинных цепочках инструментов и строгом следовании формату. Это не приговор, но архитектура должна учитывать слабые места.
Первое правило — не отдавайте модели всю власть. Пусть LLM предлагает следующий шаг, но Python-код проверяет, что такой шаг разрешен. В примере route() пропускает только четыре значения. Все остальное уходит в безопасный fallback.
Второе — ограничивайте инструменты. local_search() читает только файлы внутри SWARM_WORKSPACE и только расширения из белого списка. Для бизнес-сценария этого мало: добавьте allowlist директорий, маскирование секретов, лимиты размера файлов и аудит всех операций.
Третье — разделяйте роли. Один промпт, который одновременно ищет, пишет, проверяет и принимает решение, будет ошибаться тише. Отдельный критик не делает систему магически надежной, но создает место, где можно формализовать проверку: факты без источников, рискованные действия, неподтвержденные числа, выход за scope.
Четвертое — держите лимит итераций. Любой агентный рой может зациклиться: критик просит улучшений, строитель переписывает, планировщик снова отправляет к критику. MAX_ITERATIONS нужен не для красоты, а как предохранитель.
Приватность: что остается локальным, а что нет
Если Ollama работает локально, модельные запросы не уходят в облако Ollama. Но приватность всей системы зависит не только от модели. Проверьте три слоя:
- инструменты: нет ли в них веб-запросов, телеметрии, внешних API и загрузки файлов;
- зависимости: не включены ли облачные трассировки, удаленные callback handlers или сторонние observability-сервисы;
- сеть: не открыт ли
11434наружу без необходимости.
Для рабочей станции нормальная конфигурация — слушать только localhost. Для локального сервера лучше ставить reverse proxy с аутентификацией или вообще не публиковать Ollama в сеть. Если агент получает доступ к внутренним документам, считайте вывод модели недоверенным текстом: он может содержать подсказки выполнить опасное действие или раскрыть данные в следующем шаге.

Где такая система полезна
Локальный рой хорошо подходит для задач, где данные важнее доступа к самым новым знаниям из интернета.
Документация и внутренние базы знаний: агент ищет устаревшие разделы, готовит черновики, предлагает структуру, собирает вопросы для владельцев продукта.
Разработка: локальный анализ README, конфигов и кода без отправки репозитория во внешний чат. Для автоматического изменения файлов нужен отдельный слой разрешений и review, но как ревьюер и навигатор по проекту такой рой уже полезен.
Операционные отчеты: сбор заметок из локальных папок, первичная классификация, подготовка summary для команды.
Комплаенс-чувствительные процессы: черновая обработка документов, которые нельзя отправлять в SaaS. Здесь особенно важно не делать юридических выводов автоматически: агент может готовить структуру и находить несостыковки, но решение остается за человеком.
Где локальный рой не лучший выбор
Если вам нужен лучший доступный reasoning, сложная математика, свежие новости, многоязычная юридическая экспертиза или гарантированно строгий tool calling, локальная модель среднего размера будет уступать сильным облачным моделям. Иногда честная гибридная схема лучше: приватные документы обрабатываются локально, а обезличенные задачи уходят в облако.
Не стоит запускать автономных агентов с правом писать в продакшен, отправлять письма, двигать деньги или менять инфраструктуру без ручного подтверждения. LangGraph дает контрольные точки, но не отменяет базовую инженерную дисциплину: least privilege, audit log, dry run, тестовая среда, rollback.
Как развивать пример дальше
После базового запуска есть пять очевидных улучшений.
- Добавить RAG: индексировать локальные документы в векторную базу и передавать агенту только релевантные фрагменты.
- Ввести human approval: перед записью файла или внешним API-вызовом останавливать граф и ждать подтверждения.
- Разнести модели: маленькую модель использовать для маршрутизации, более сильную — для финальной генерации и критики.
- Добавить evals: хранить тестовые задачи и сравнивать качество ответов после смены модели или промптов.
- Подключить UI: показывать состояние графа, последние чекпоинты, решения планировщика и замечания критика.
Главный принцип: не пытайтесь сразу построить универсального автономного сотрудника. Начните с узкого процесса, где входные данные лежат локально, критерии качества понятны, а ошибка не приводит к необратимому действию. Для такого класса задач LangGraph и Ollama дают редкую комбинацию: локальность, прозрачную оркестрацию и достаточно простой путь от эксперимента к внутреннему инструменту.







