
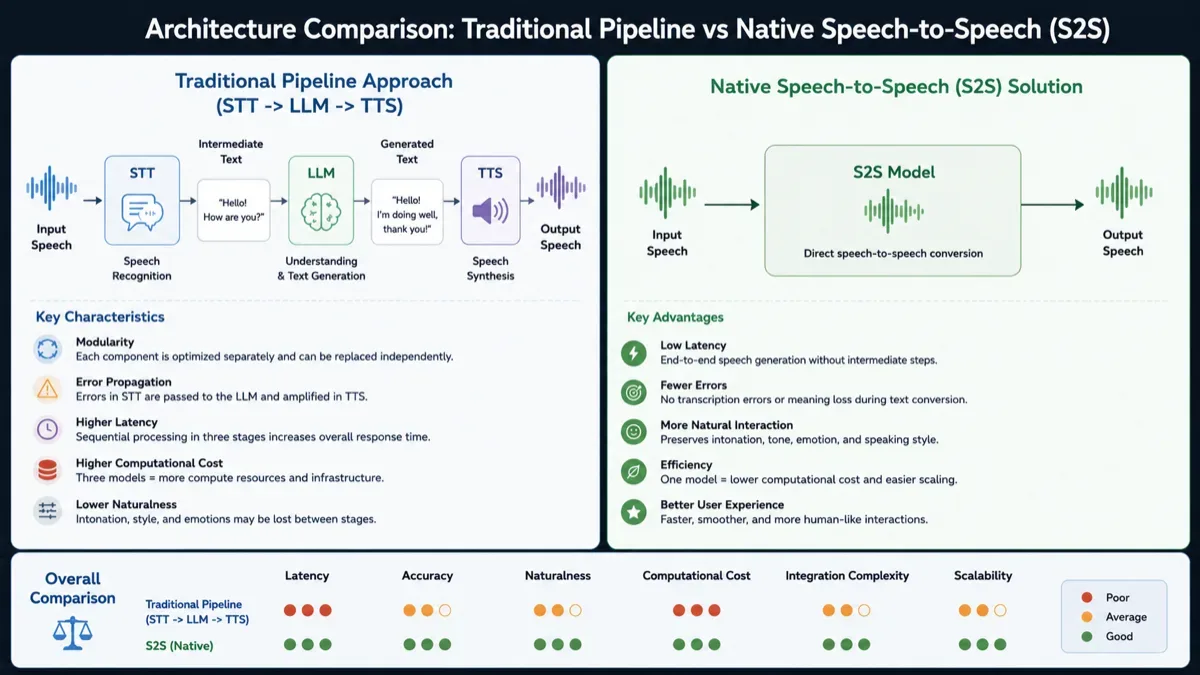
Until recently, building a voice AI assistant usually meant stitching together three separate systems: speech recognition (STT), a large language model (LLM), and text-to-speech synthesis (TTS). That cascade architecture worked, but it had one painful flaw: latency. A two-to-four-second pause after every user phrase makes a conversation feel less like a dialogue and more like a walkie-talkie exchange.
By mid-2026, the industry has moved toward native Speech-to-Speech (S2S) models and real-time audio APIs. Instead of converting every utterance into text, waiting for a model response, then synthesizing audio at the end, these systems process audio streams continuously. That shift makes it possible to approach human conversational timing, roughly 300-700 ms in good conditions, while preserving tone, hesitation, emotional cues, and interruptions.
This guide compares three practical options for business voice agents: OpenAI Realtime API, Hume AI with its Empathic Voice Interface, and ElevenLabs Conversational AI. The goal is not to crown one universal winner. It is to help you choose the right stack for support, sales, healthcare intake, coaching, onboarding, or interactive media.
The main contenders
1. OpenAI Realtime API
OpenAI’s real-time audio interface is built around bidirectional streaming, usually over WebSockets, and is designed for low-latency conversational agents. The key difference from older voice stacks is that the model can handle audio natively instead of treating speech as a temporary text transcript.
For business teams, the main appeal is speed plus tool use. A voice agent can listen, respond, call functions, fetch account data, update a booking, or trigger a workflow while keeping the conversation fluid. The tradeoff is integration complexity: this is a developer-first API, not a one-click voice widget.
2. Hume AI EVI
Hume AI focuses on empathic voice interaction. Its Empathic Voice Interface, or EVI, is designed to detect emotional signals in speech and adapt the response style accordingly. That makes it especially relevant for coaching, mental wellness, patient support, customer satisfaction analysis, and any workflow where tone matters as much as the literal words.
The important distinction is that Hume is not only a voice generator. It is an emotional signal system wrapped into a conversational interface. If your agent needs to notice frustration, uncertainty, sarcasm, or distress, Hume deserves a serious look.
3. ElevenLabs Conversational AI
ElevenLabs became known for high-quality voice synthesis, voice cloning, and expressive generated speech. Its Conversational AI product brings that strength into real-time agents.
For many companies, ElevenLabs is attractive because the voices sound polished and brandable. If your product needs a recognizable voice, a media character, a game NPC, or a premium concierge feel, this can matter more than shaving the last 150 ms off latency.
The real comparison: latency, emotion, and interruptions
When a business deploys a voice AI agent, the demo is not the hard part. The hard part is making the agent survive real users: people interrupt, mumble, change their mind, get annoyed, speak over background noise, and expect the system to respond naturally.
1. Latency
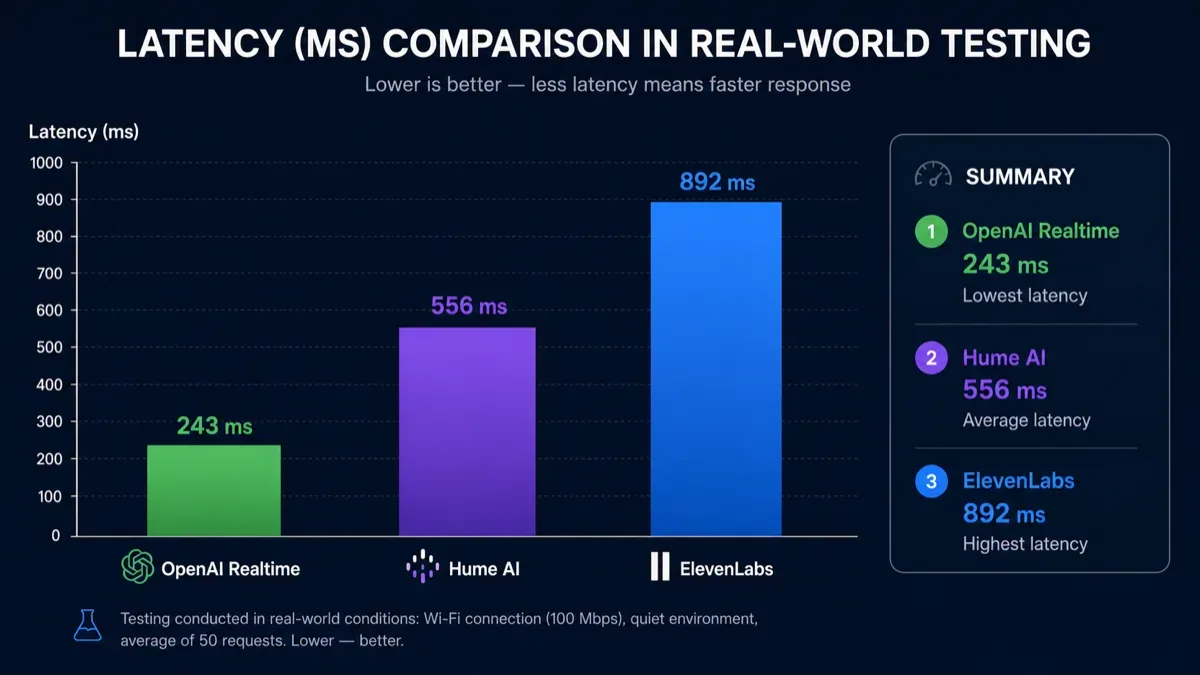
Human turn-taking is fast. In a normal conversation, people often begin responding within a few hundred milliseconds. Once an AI agent regularly crosses the 800 ms mark, the interaction starts to feel mechanical.
- OpenAI Realtime API: Typically the strongest option for raw responsiveness, with a practical target around 300-400 ms in optimized network conditions. It is a strong fit when low latency is the product experience.
- Hume AI EVI: Usually sits closer to 500-700 ms. Some of that extra time is the cost of deeper acoustic and emotional interpretation, which may be worthwhile in empathy-heavy use cases.
- ElevenLabs Conversational AI: Often lands around 500-800 ms, depending on the selected LLM, voice settings, and integration pattern. The upside is voice quality and production polish.
2. Emotional range and sarcasm
Imagine a customer says, “Oh, sure, this is the best support experience of my life” while clearly sounding irritated. A basic text-only system may treat that as praise. A better voice AI stack should understand the emotional contradiction.
- Hume AI: The strongest candidate for emotional understanding. Its core value is detecting affective signals from prosody, pitch, tempo, and other vocal features. In a support scenario, it is more likely to respond with empathy instead of taking sarcastic words literally.
- OpenAI Realtime API: Very natural and fast, and it can infer sarcasm from context or obvious tone. It is less specialized than Hume for dedicated emotional analytics, but it has strong general conversational intelligence.
- ElevenLabs: The generated voices are often the most cinematic and pleasant. The weak point is not voice realism; it is dynamic emotional interpretation of the customer. For a branded voice experience, it shines. For live emotion analytics, it may need additional tooling.
3. Interruption handling
Real conversations are messy. People interrupt agents, agents need to stop speaking quickly, and the system must decide whether a cough, background speech, or short backchannel is a true interruption.
- OpenAI Realtime API: Interruption handling is one of its strongest advantages. Since audio streaming and response generation are tightly coupled, the system can stop the current audio output quickly when the user starts speaking.
- Hume AI: Strong in emotionally aware turn-taking and backchanneling. It is designed to treat conversation as a live interaction, not a sequence of isolated prompts.
- ElevenLabs: Conversational AI can handle interruptions well in its managed environment, but custom API integrations may require careful client-side VAD, buffering, and turn-taking logic.
Comparison table: business-relevant tradeoffs
| Parameter | OpenAI Realtime API | Hume AI EVI | ElevenLabs Conversational AI |
|---|---|---|---|
| Typical latency | 300-400 ms | 500-700 ms | 500-800 ms |
| Voice quality | Excellent and natural | Good, emotion-focused | Excellent, often best-in-class |
| Customer emotion detection | Good general inference | Deep emotional analysis | Limited unless paired with another system |
| Interruption handling | Excellent | Strong | Good, integration-dependent |
| Estimated cost per minute | ~$0.12-$0.25 | ~$0.07+ | ~$0.15-$0.30 |
| Integration complexity | High | Medium | Low to medium |
| Best fit | Fast transactional agents | Empathic support and coaching | Branded voice and media experiences |
These numbers should be treated as planning ranges, not procurement quotes. Voice AI pricing changes quickly, and real costs depend on audio duration, model choice, token usage, concurrency, storage, telephony fees, and whether you route calls through a platform such as Twilio or your own infrastructure.
Integration architecture: the voice engine is not the whole product
A real business agent needs more than a beautiful voice. It needs access to CRM data, policies, booking systems, knowledge bases, payment status, order history, and escalation rules.
A practical architecture often looks like this:
- The customer speaks through a browser, mobile app, or phone call.
- The voice engine receives the live audio stream.
- When the user asks for an action, the agent triggers a tool call.
- An orchestration layer validates the intent and calls internal APIs.
- The voice engine returns the answer in the same conversation.
For the orchestration layer, LangGraph is a useful framework because it lets teams model agent workflows as stateful graphs instead of a single prompt. That matters when a voice assistant needs to check permissions, ask follow-up questions, branch into different flows, or recover from failed tool calls.
Which platform should you choose?
Choose OpenAI Realtime API if:
- You need the lowest possible conversational latency.
- Your product already uses OpenAI models and tool calling.
- The agent must handle interruptions naturally.
- You have engineers who can manage WebSockets, audio streaming, and stateful sessions.
OpenAI is the strongest default for fast, transactional agents: booking assistants, internal copilots, sales qualification, support triage, and voice workflows where responsiveness directly affects conversion.
Choose Hume AI if:
- Emotional awareness is central to the product.
- You are building coaching, therapy-adjacent support, patient intake, customer satisfaction analysis, or wellness experiences.
- You need to detect frustration or uncertainty before the user states it explicitly.
- You can accept slightly higher latency in exchange for deeper affective signals.
Hume is most compelling when voice is not just an input channel, but an emotional context layer.
Choose ElevenLabs if:
- Your brand needs a memorable voice.
- You care about voice quality, character, and tone more than absolute minimum latency.
- You want a faster path to a working conversational prototype.
- You are building media, games, education, entertainment, or premium concierge flows.
ElevenLabs is the strongest choice when the voice itself is part of the product identity.
A simple decision rule
If you are building a customer support agent that must answer quickly and execute tasks, start with OpenAI Realtime API. If you are building an emotionally sensitive assistant, evaluate Hume AI first. If your core differentiator is a polished, branded, memorable voice, start with ElevenLabs.
For many mature teams, the final architecture may combine more than one layer: OpenAI for real-time reasoning and tool use, ElevenLabs for custom voice identity, Hume for emotion analytics, and LangGraph for orchestration. The winning stack is not always the one with the best demo. It is the one whose latency, cost, emotional intelligence, and operational complexity match the job your business actually needs done.







